Clickhouse
https://github.com/clickhouse/clickhouse
GitHub - ClickHouse/ClickHouse: ClickHouse® is a free analytics DBMS for big data
ClickHouse® is a free analytics DBMS for big data. Contribute to ClickHouse/ClickHouse development by creating an account on GitHub.
github.com
아래 내용글들은 kakaoif2020 에서 소개된 내용을 정리한것입니다.
https://tv.kakao.com/channel/3693125/cliplink/414129353
clickhouse란
- Distributed analytical column-oriented DBMS
분석용 디비에서는 중요하지 않는 기능들을 축소하고, 속도에 중점을 두었음.
- 트랜잭션을 축소
- 데이터의 변경이나 삭제 기능을 매우 제한적으로 함.
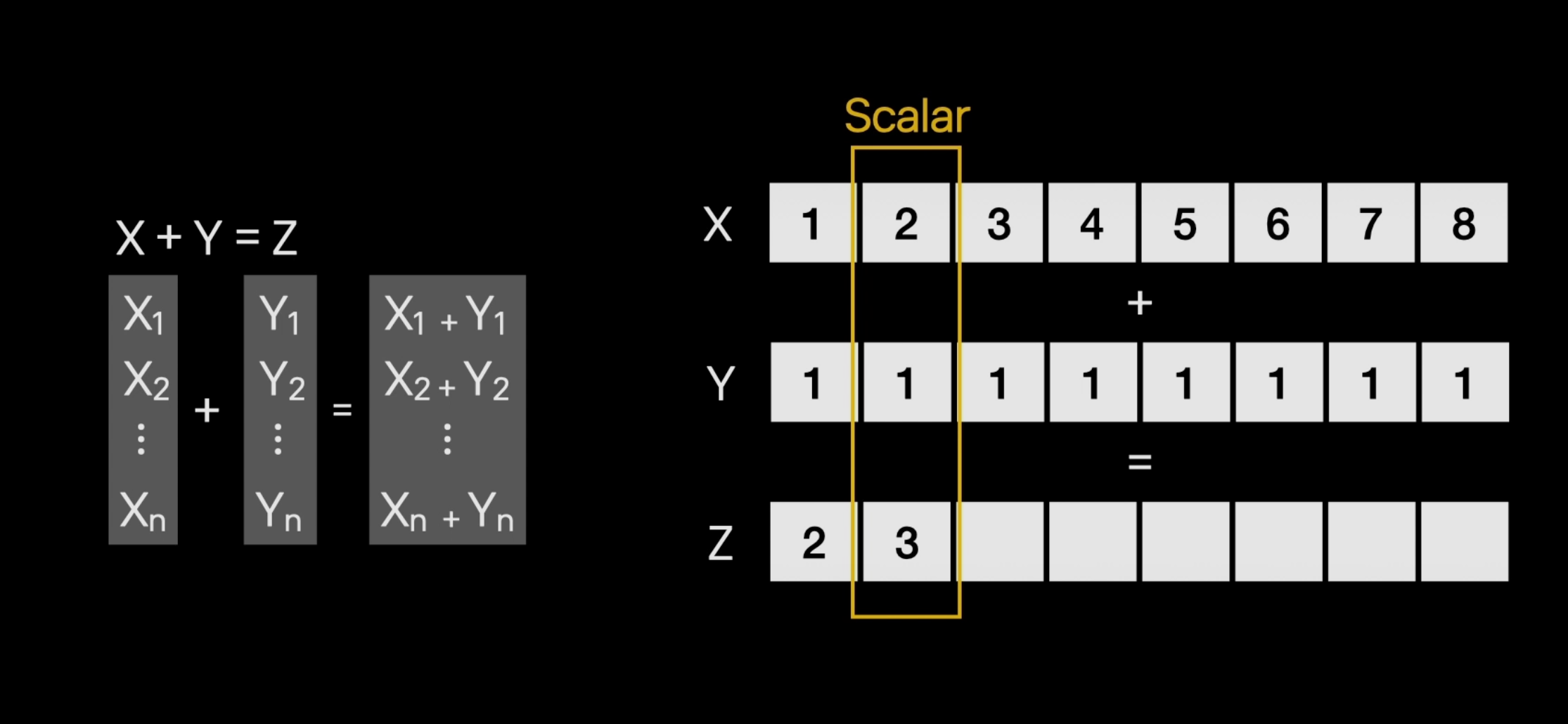
1. Vectorized Processing
- 한번에 여러개의 연산을 수행할 수 있음. → CPU의 SIMD 명령어 집합을 사용


2. MergeTree

clickhouse 는 여러개의 테이블 엔진을 지원함.
가장 널리 쓰이는 방식은 MergeTree
테이블엔진은 데이터를 저장하고 조회하는 방식을 결정

테이블의 데이터는 파티션 단위로 나뉘어 저장 되는데, 파티션은 파티션 키로 지정된 데이터 컬럼기준으로 나뉩니다.
각 파티션은 인덱스 정보가 있고, 테이블을 구성하는 컬럼에 대한 데이터 파일이 포함됩니다.
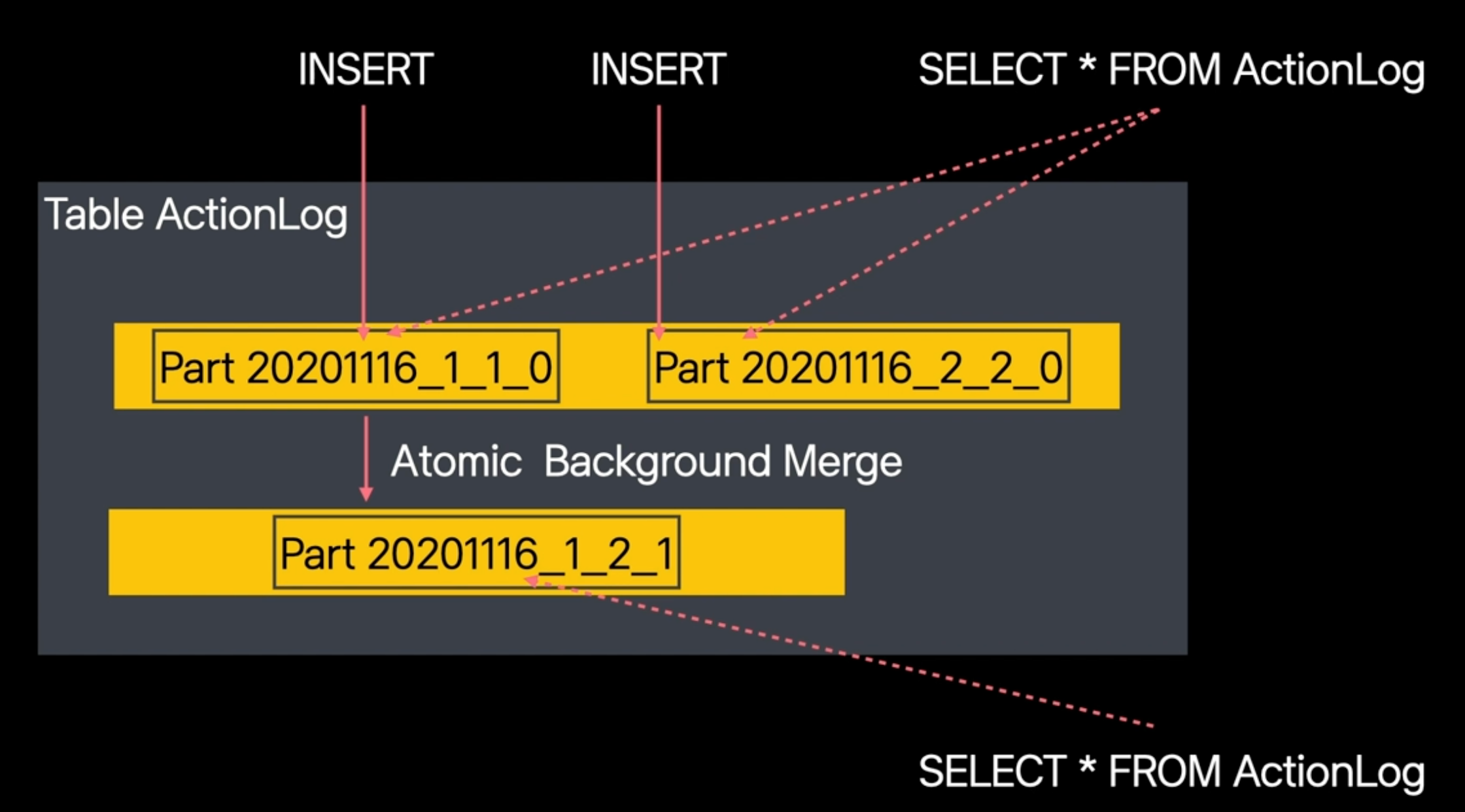
하나의 파티션은 여러개의 파트로 구성되는데, 머지트리 테이블 엔진은 데이터를 저장할때, 개별적인 파트로 나뉘어서 저장합니다.
데이터를 저장할때, 새로운 파트로 만들어서 저장하기 때문에 insert 현상이 매우 가볍습니다.
데이터 조회시 개별 파트들에서 데이터를 취합하는데, 이것을 더 빠르게 하기 위해 파트들을 백그라운드에서 Merge합니다
Merge가 완료되면 데이터를 모아서 압축하기 때문에 저장공간을 줄일 수 있고, 인덱스 검색 횟수도 줄기 때문에 조회속도도 빨라 집니다.
3. Primary Index
파티션 안에는 Primary 인덱스정보가 있고, Primary 인덱스는 Sparse하게 구성되어있기 때문에 대용량 데이터를 인덱스 하더라도 메모리 공간을 적게 사용합니다
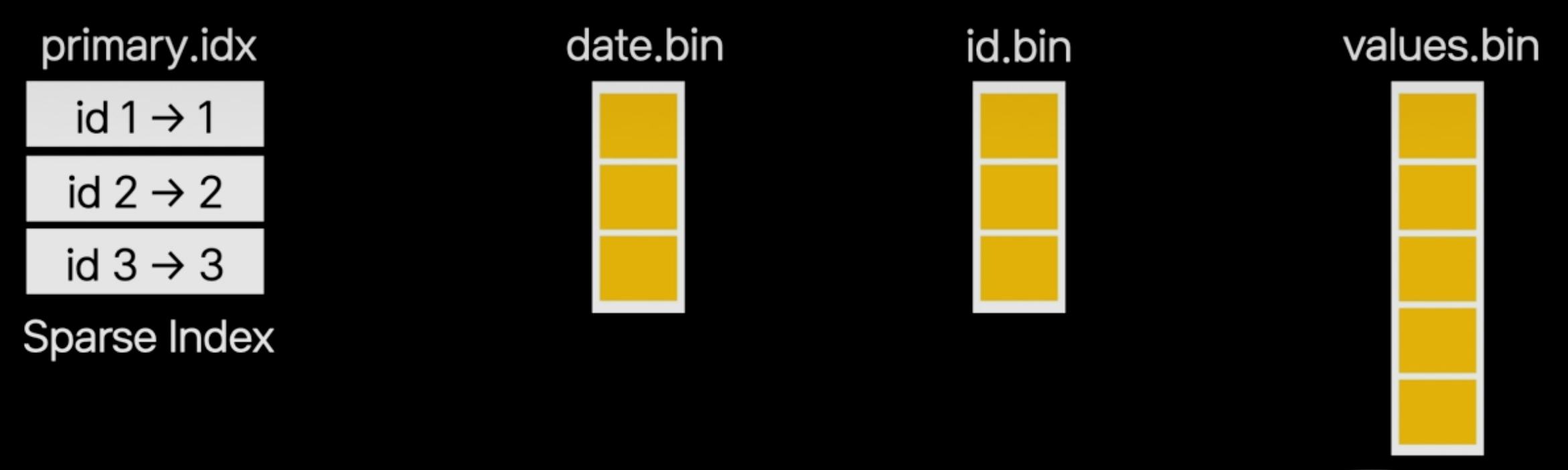
Column Oriented DB 이기 때문에 컬럼별로 파일을 나뉘어서 저장하고, 필요한 컬럼만 조회합니다
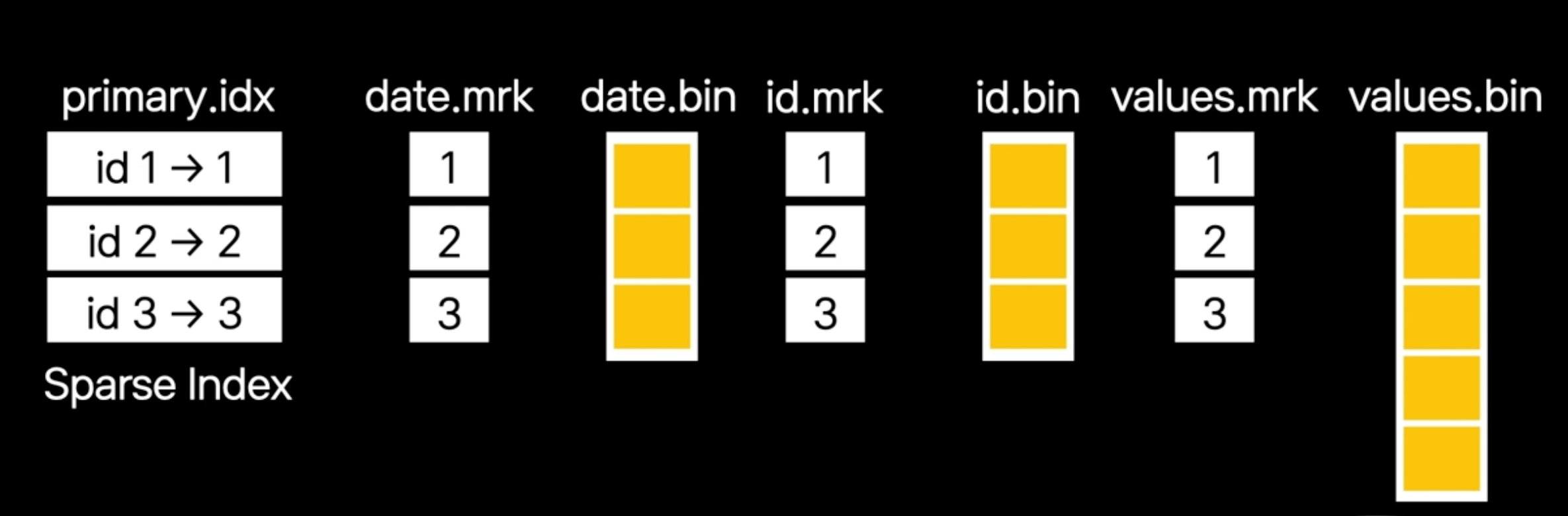
Primary 인덱스에는 번호가 매겨지고, 각 번호는 데이터 파일의 시작위치를 mrk파일에서 참조합니다
각각의 데이터파일마다 mrk 파일이 존재하고, mrk 파일은 인덱스 번호에 해당하는 데이터의 위치를 찾는 네비게이터 역할을 합니다.
4. Data Skipping Index
인덱스에 포함되지 않는 컬럼은 어떻게 빠르게 조회할까?
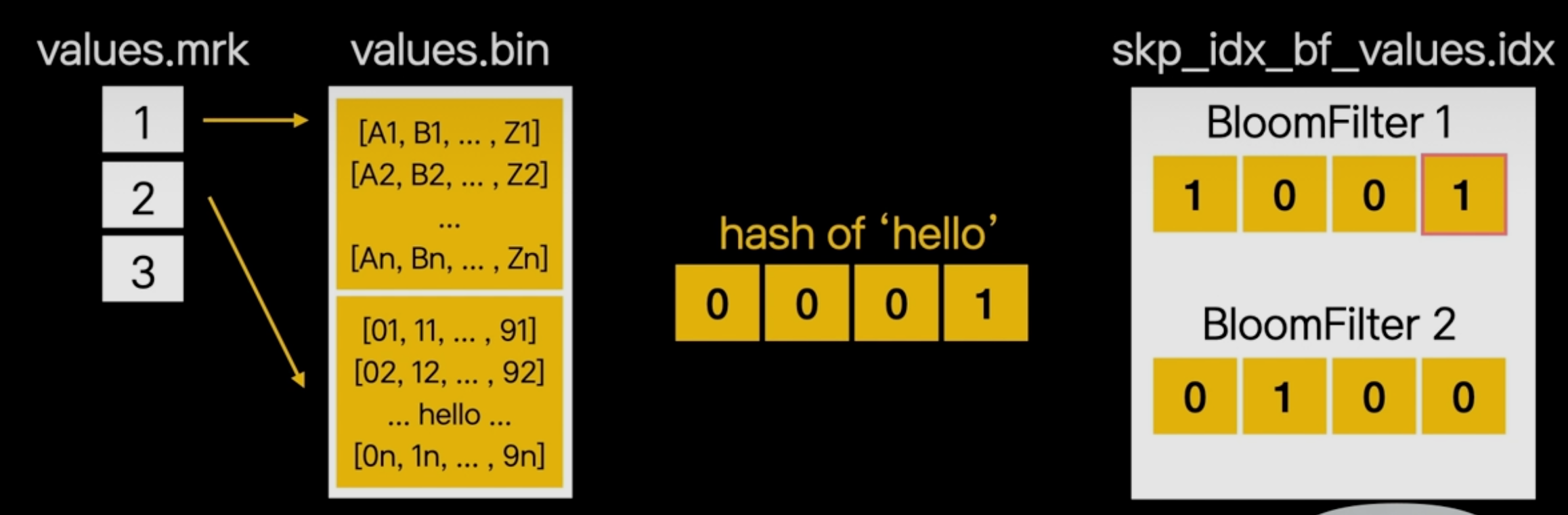
Primary 인덱스는 데이터를 물리적으로 정렬하고, 데이터 skipping index 는 여기에 스캔을 위한 자료구조를 추가합니다.
string array 값을 가지는 values 컬럼에서 hello 라는 단어를 찾으려고 합니다.
배열을 하나하나 찾다보면 오래걸리겠죠?
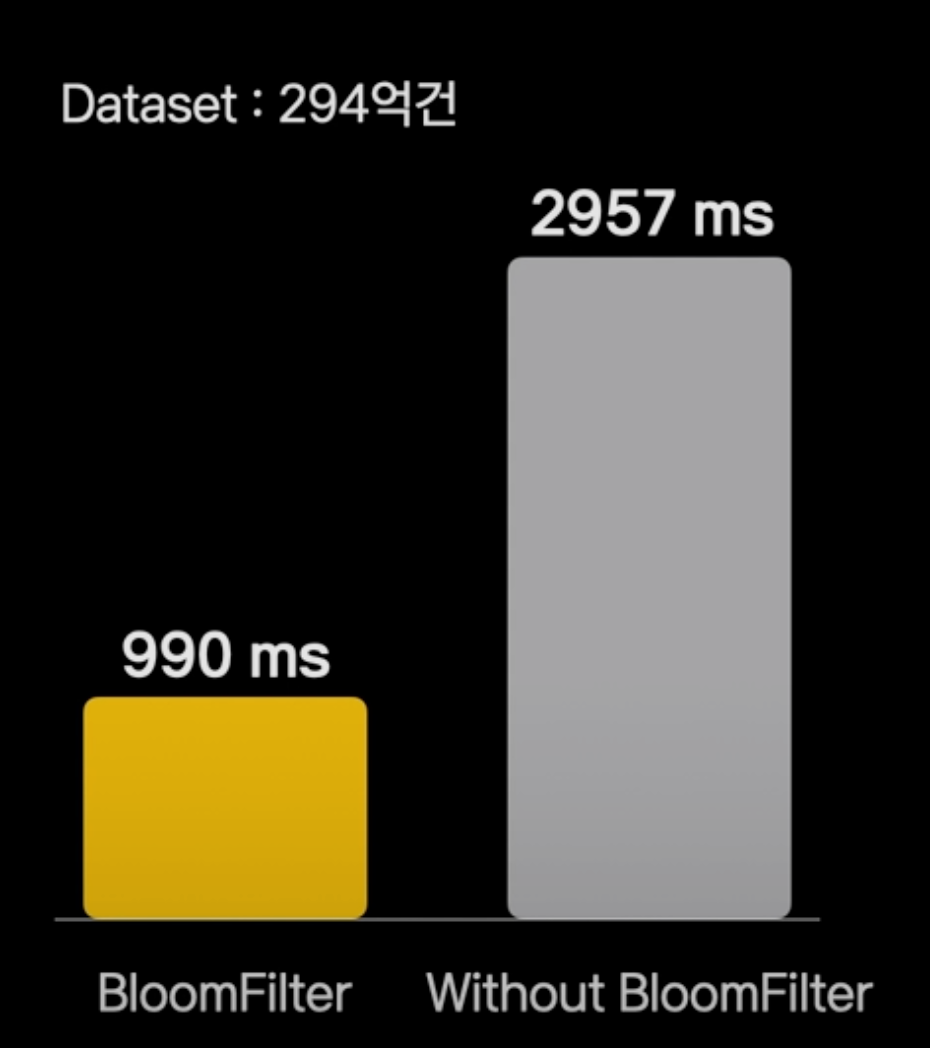
저희는 이 연산을 빠르게 만들기 위해서 bloom filter를 array 타입으로 확장해서 오픈소스에 기여했다
bloom filter는 집합의 원소의 포함여부를 검사하는데 사용하는 자료구조이고, 확률적인 마법을 사용하기 때문에 긍정 오류가 발생하지만, 저장공간을 효율적으로 사용이 가능하다.
hello의 문자열의 해시값을 찾고 각 블롬필터의 비트값이 참이되는지를 검사하면 됩니다.
5. Replication : 복제
클릭하우스는 기본적으로 비동기 멀티마스터 복제 방식입니다.
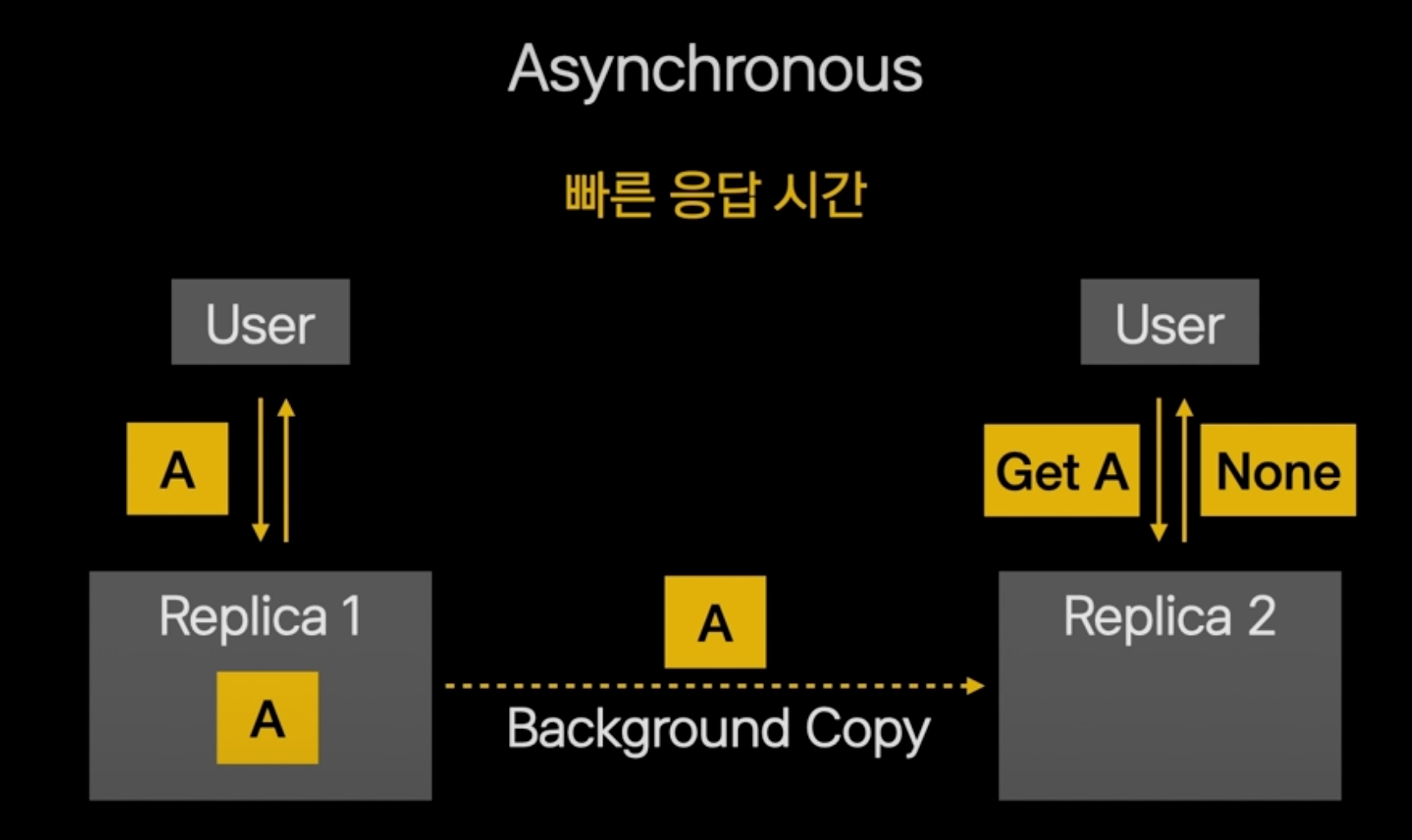
요청받은 서버가 데이터를 저장하면 바로 사용자에게 응답을 보내고, 데이터 복제는 백그라운드에서 진행합니다.
그렇기 때문에 데이터를 저장한 직후에 리플리카2에게 데이터 A를 요청하면, 데이터가 없다고 응답하는 케이스가 생깁니다
이렇지만, 백그라운카피가 빠르기 때문에 분석용 디비에 사용하기에 무리가 없었고, 응답시간이 빠른게 장점입니다.
데이터 유실이 걱정된다면 Insert Column Option을 참고하시기 바랍니다.

멀티마스터 방식이기 때문에, 복제참여하는 모든 멤버가 데이터를 추가할 수 있습니다.
각각의 데이터 리플리카는 자신에게 들어오는 데이터를 형식에 맞춰서 저장하고, 압축합니다.
다른 복제본은 압축된 데이터를 카피하는 연산만 수행하기 때문에, 부하가 분산됩니다.
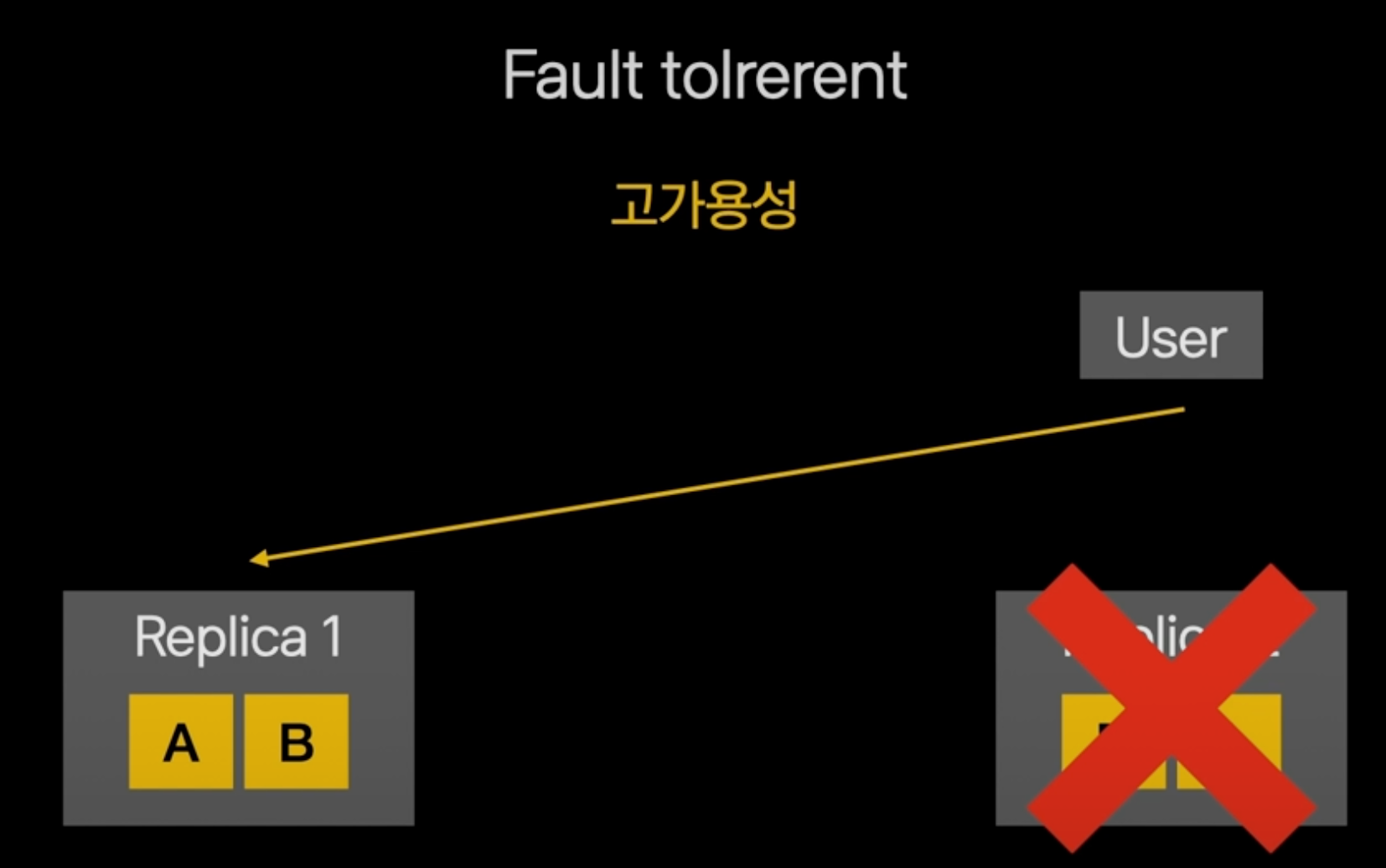
복제를 사용하면 더 견고해지고, 리플리카2서버의 하드웨어가 고장났을 때, user는 리플리카1을 통해서 서비스를 이어나갈 수 있습니다.
6. Distributed Processing
분산 쿼리를 통해 일을 나누어서 하는 방법을 설명
클릭하우스 클러스터는 데이터를 여러개의 샤드에 나눠서 저장합니다
분산 쿼리는 여러개의 샤드에서 데이터를 모아서 사용자에게 리턴하고,
ActionLog_Dist 테이블 데이터를 조회하는 시나리오로 설명하겠습니다.
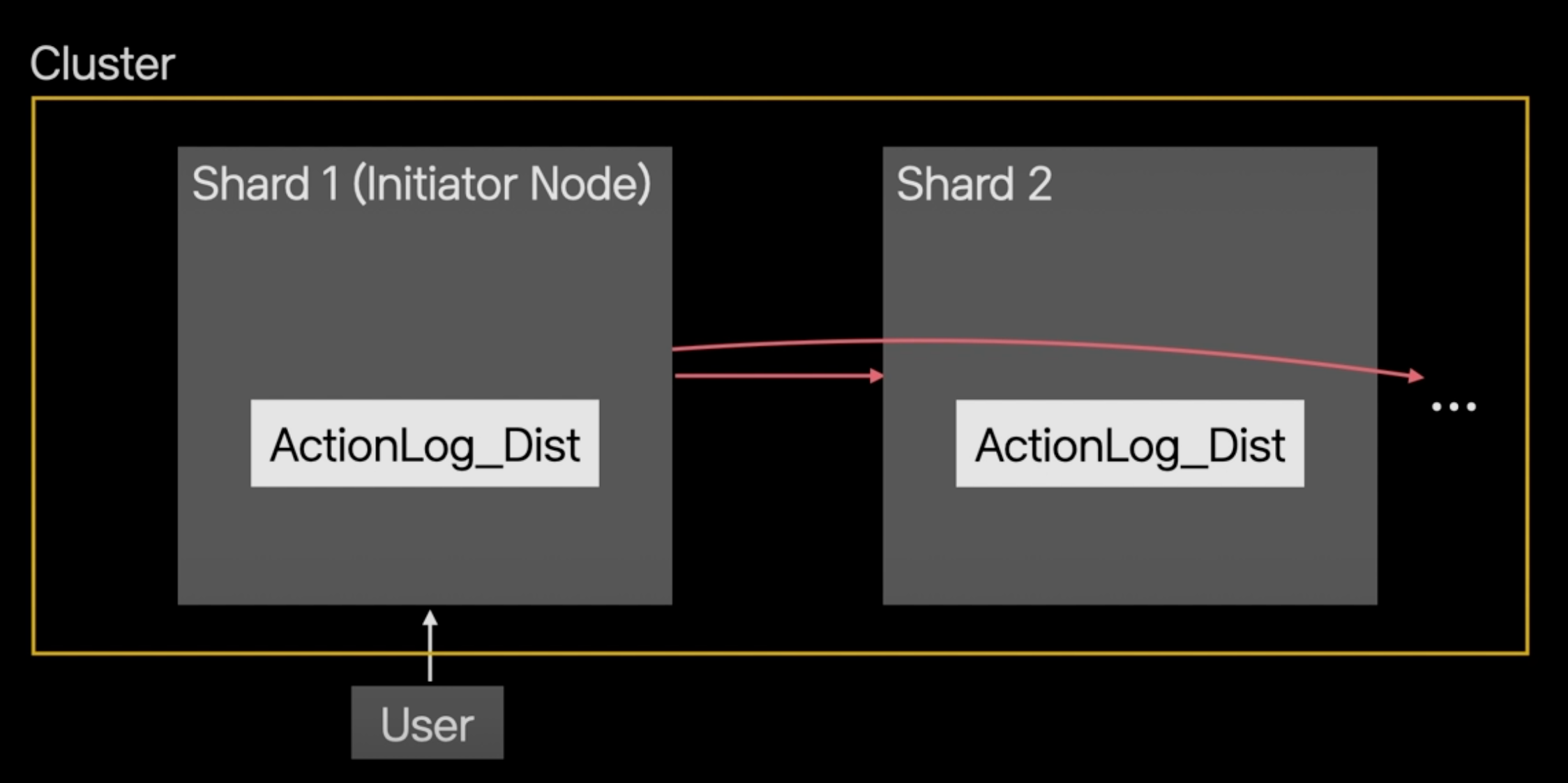
사용자의 쿼리를 처음 받은 서버를 Initiator Node라고 하고, Initiator Node는 쿼리를 모든 샤드에게 전달합니다.
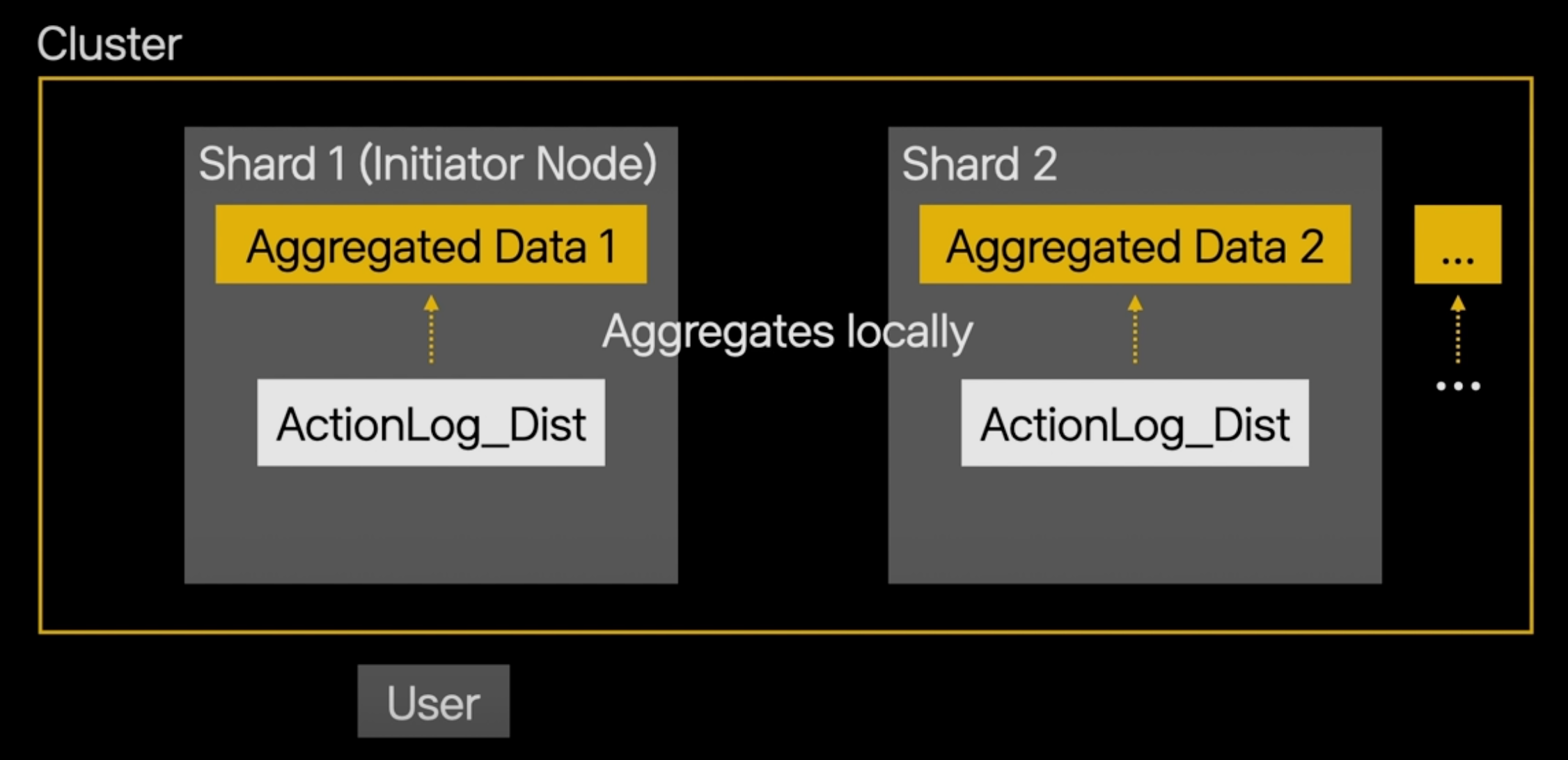
각각의 샤드는 자신이 가진 데이터를 locally하게 집계해서 중간단계 결과를 만들고, 이를 Initiator 노드에게 전달합니다
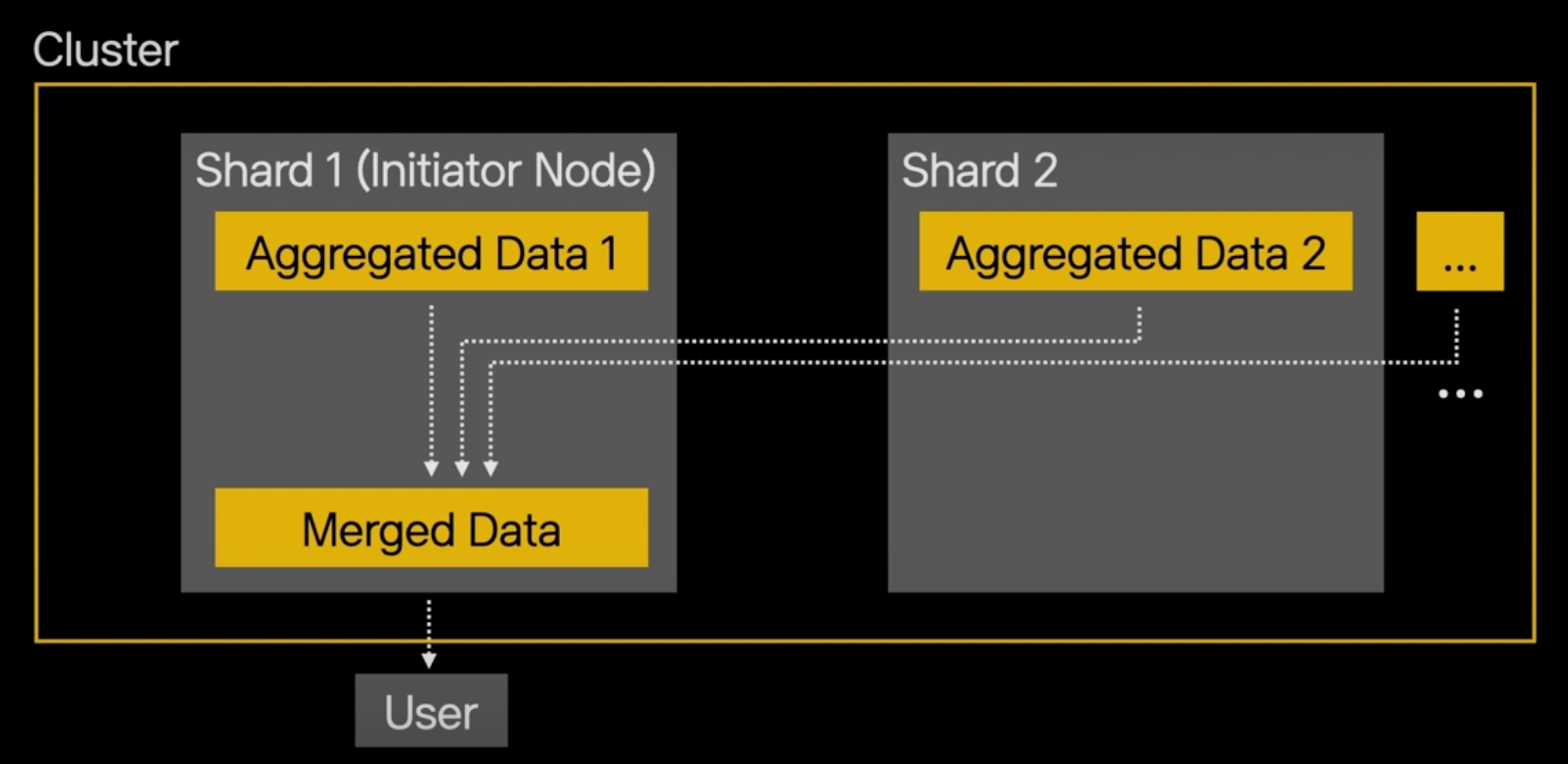
Initiator Node는 Merge해서 사용자에게 최종 결과를 전달합니다.
